with Sergey Levine
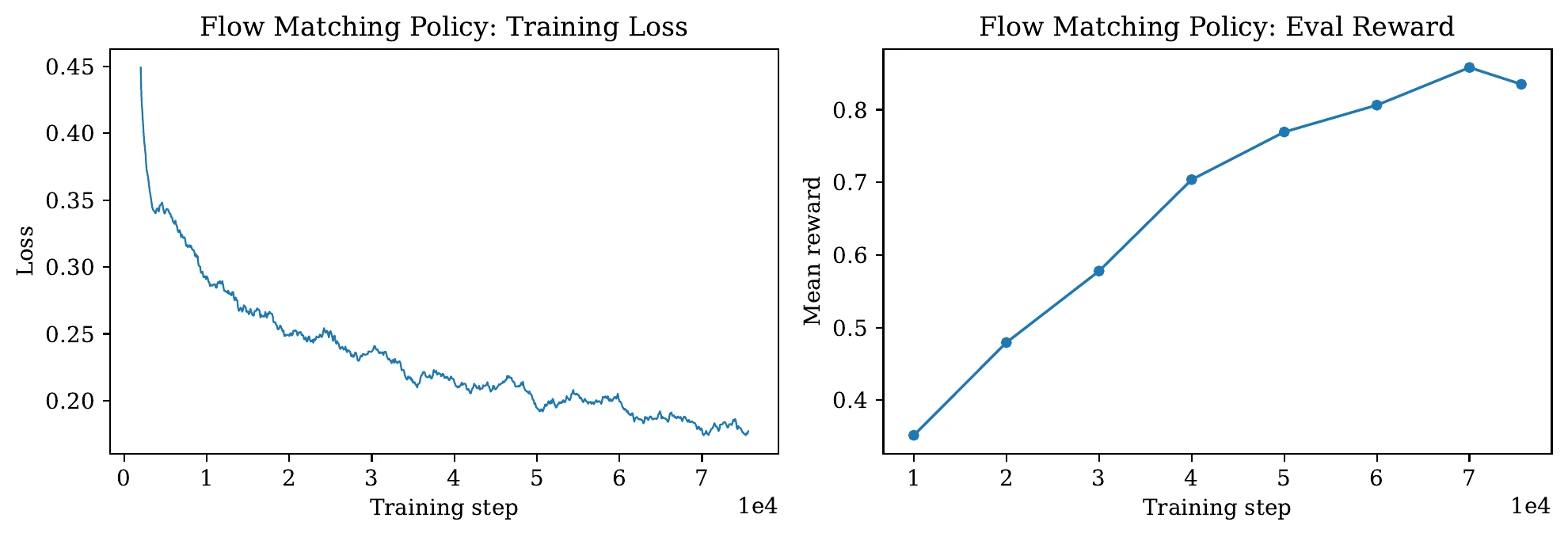
Action-chunking behavioral cloning with MSE and flow matching policies for the Push-T environment.
with Angjoo Kanazawa and Alexei Efros
Keypoint tracking, DLT camera calibration with RANSAC and bundle adjustment, 3D cube projection, and affine/homography transforms from scratch.
Direct CNN regression, ResNet-18 and DINOv3 transfer learning, and U-Net heatmap prediction with soft-argmax for 68-point facial keypoint detection.
Probed Vision Encoders with linear classifiers and trained patch-level SAEs to discover interpretable sparse dictionary features (SDFs) defining demographic traits, revealing the heavy influence of reconstruction error in SAE-based debiasing.
Double DQN with frozen pretrained vision encoders (AIMv2, V-JEPA 2), PCA whitening, and optional dueling architecture for VizDoom FPS environments.